2-1. 기업 프로젝트 2주차 (데이터 전처리)
꾸준히 업로드를 하려했지만 5개 기업 이력서 작성한다고 업로드를 많이 미뤘다..(핑계)
지난번 데이터 설명에 이어 제공 받은 데이터를 전처리 하기 위한 파이썬 코드를 설명해보려고 한다.

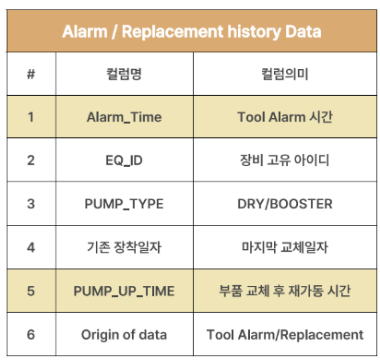
1) 데이터 Load
데이터 경로에 따라 Colab환경에서 FDC와 Alarm 데이터 불러오기
file_path1 = '/content/drive/MyDrive/ASAC_4기_기업프로젝트_SK하이닉스/00.Data_set/ASAC_4기_Dataset_Alarm_22년PoC.csv'
file_path2 = '/content/drive/MyDrive/ASAC_4기_기업프로젝트_SK하이닉스/00.Data_set/ASAC_4기_Dataset_FDC_Summary_Fullset_22년PoC.csv'2) Datetime 변환
FDC 수치형 데이터 1,2 와 alarm 1,5 컬럼에 해당하는 날짜 시간 데이터에 대해
2022-07-30 오후 01:00:00 와 같은 형태로 존재 하는 날짜 데이터를 파이썬이 인식가능한 형태로 변환시켜줘야함
--> 2022-07-30 13:00:00
def convert_to_24hr(date_str):
# 오전/오후 문자를 AM/PM으로 변환
date_str = date_str.replace("오전", "AM").replace("오후", "PM")
# 24시간제 형식으로 변환
date_obj = datetime.strptime(date_str, "%Y-%m-%d %p %I:%M:%S")
# 변환된 객체를 문자열 형식으로 반환
return date_obj.strftime("%Y-%m-%d %H:%M:%S")
# 'start_dt_tm' 열의 데이터를 24시간제 형식으로 변환하여 업데이트
df['start_dt_tm'] = df['start_dt_tm'].apply(convert_to_24hr)
df['end_dt_tm'] = df['end_dt_tm'].apply(convert_to_24hr)
# 'start_dt_tm' 열을 datetime64[ns]로 변환
df['start_dt_tm'] = pd.to_datetime(df['start_dt_tm'])
df['end_dt_tm'] = pd.to_datetime(df['end_dt_tm'])
# 변환된 데이터 프레임의 첫 5행을 출력
print(df)def convert_to_24hr(date_str):
if pd.isna(date_str):
# 입력 값이 NaN이라면, 그대로 반환
return date_str
# 오전/오후 문자를 AM/PM으로 변환
date_str = date_str.replace("오전", "AM").replace("오후", "PM")
# 24시간제 형식으로 변환
date_obj = datetime.strptime(date_str, "%Y-%m-%d %p %I:%M:%S")
# 변환된 객체를 문자열 형식으로 반환
return date_obj.strftime("%Y-%m-%d %H:%M:%S")
# 'Time' 열의 데이터를 24시간제 형식으로 변환하여 업데이트
df_1['Time'] = df_1['Time'].apply(convert_to_24hr)
df_1['PUMP UP TIME'] = df_1['PUMP UP TIME'].apply(convert_to_24hr)
# 'Time' 열을 datetime64[ns]로 변환
df_1['Time'] = pd.to_datetime(df_1['Time'])
print(df_1)3) 데이터 프레임 병합
데이터 자체에 우리가 예측하고자 하는 잔여수명(target)y 값이 존재하지 않기 때문에 임의로 만들어 주어야한다.
Alarm 데이터의 고장시점을 FDC데이터의 공정 시간 시간 start_dt_tm 기준으로
고장시점-start_dt_tm 를 통해 잔여수명이라는 groundtruth를 만들어줘야함
start_dt_tm 기준으로 가장 가까운 Tool alarm시간을 새로운 컬럼으로 만들어 붙여야함
merged = pd.merge_asof(df1, df1_1_cleaned, left_on='start_dt_tm', right_on='Time', direction='forward')
merged1_2 = pd.merge_asof(merged, df1_1_cleaned, left_on='start_dt_tm', right_on='Time', direction='backward')
# FDC의 start_dt_tm을 기준으로 이전고장 시점(backward)와 이후 고장시점(forward)을 추가해줘야함시간 관련 컬럼에 대해서는 이후 그림으로 자세히 설명해보겠음
4) 결측치 처리
FDC 센서 데이터의 다양한 aggregation 통계값에 많은 결측치가 존재했기 때문에 이에 대한 처리가 필요했다. 우선 각 통계값별 결측치 계수를 확인해보자
for i in ['max_val', 'min_val', 'stddev_val', 'range_val','median_val', 'area_val', 'slope_val', 'p05_val', 'p10_val', 'p90_val','p95_val', 'mean_val']:
print(i,'결측치 개수는',merged1_2[i].isnull().sum())
개수는 비밀..(사실 밝혀도 상관 없을 것 같긴한데 혹시 모르니 일단 가릴게요)
존재하는 결측치를 대체 해보자
-max_val에 존재하는 결측치 ==> p95_val 값으로 대체
-min_val에 존재하는 결측치 ==> p05_val 값으로 대체
-range_val에 존재하는 결측치 ==> p95_val - p05-val 값으로 대체
def replace_stddev_if_max_equals_min(sorted_df):
for index, row in sorted_df.iterrows():
if row['max_val']==row['min_val']:
sorted_df.at[index, 'stddev_val'] = 0
replace_stddev_if_max_equals_min (merged1_5)
def analyze_and_clean_data(df):
# 각 컬럼별 결측치 개수 출력
for col in ['max_val', 'min_val', 'range_val', 'mean_val', 'median_val', 'stddev_val', 'p05_val', 'p10_val', 'p90_val', 'p95_val']:
print(f'{col} 결측치 개수는', df[col].isnull().sum())
# 'mean_val'과 'stddev_val'이 둘 다 NaN인 행의 개수 계산 및 출력
na_both = df[df['mean_val'].isna() & df['stddev_val'].isna()]
print('mean_val과 stddev_val이 둘 다 NaN인 행의 개수:', len(na_both))
# 'mean_val' 열에서 결측치를 포함하는 행을 제거
cleaned_df_1 = df.dropna(subset=['mean_val'])
return cleaned_df_1
# 함수 사용
merged1_6 = analyze_and_clean_data(merged1_5)
# 결과 출력
print(merged1_6.head())
print('제거 후 행의 개수:', len(merged1_6))-stddev_val 표준편자 센서데이터 컬럼에 대해서는 max_val과 min_val 의 값 차이가 0이라면 결측치 값을 0으로 대체하기
결과

모든 결측치가 처리 되었다.
5) 데이터 프레임 pivot 하기

하나의 공정 스텝에 대한 센서 파라미터 값이 19개 씩 존재하기 때문에 하나의 공정 스텝에 대한 정보는 하나의 행으로 표현하는게 시계열데이터의 input 데이터 형태로 적합했다. 이를 코드로 구현하면
def create_pivot_table(df):
# 피벗 테이블 생성
pivot_df = df.pivot_table(
index=[
'WAFER_ID', 'PROD_CD', 'EQ_ID', 'OPER_ID', 'RCP_ID', 'STEP_NM',
'TA_tm_before', 'start_dt_tm', 'end_dt_tm', 'TA_tm_after', 'P_Time'
],
columns='PRMT_NM',
values=['max_val', 'min_val', 'stddev_val', 'mean_val', 'range_val', 'median_val'],
aggfunc='first'
).reset_index()
# 컬럼 이름 변경
pivot_df.columns = [f'{val}_{prmt}' if prmt != '' else val for val, prmt in pivot_df.columns]
return pivot_df
# 함수 사용
pivot_df_1 = create_pivot_table(merged1_6)
# 결과 출력
print(pivot_df_1)해당 코드로 2,349,407개의 행이 123,653개로 줄어들고 21개의 컬럼개수가 107개로 증가했다. (이후 파생변수 추가로 인해 컬럼은 계속 증가할 예정)
여기 까지 데이터 병합 및 결측치 처리와 pivot table 관한 전처리가 완료 되었고 다음에는 시간 관련 파생변수 생성과 성능 개선을 위한 전처리를 진행해보겠다.
중간중간 생략된 전처리가 있다보니 데이터 프레임 변수명이 이어지지 않아서 혼선이 있을 수 있는데 진행한 전처리가 뭐가있는지 정도만 보시면 좋을 것 같습니다!.. 궁금한게 있다면 질문해주세요!